跳转到主要内容在流存储库 S3Stream 中,S3 存储是另一个核心组件。WAL 仅用于写入加速以及故障恢复,S3 才是数据真正存储的地方。海量的数据正在往云端聚集,对象存储已经成为了大数据和数据湖生态事实上的存储引擎,我们今天可以发现大量的数据密集型软件正在从文件 API 迁移到对象 API,以 Kafka 为代表的流式数据入湖也是大势所趋。
S3Stream 基于 Object API 提供流式数据高效的读取和摄入,然后通过存算分离的架构将 Apache Kafka 的存储层对接至对象存储,充分获得了共享存储带来的技术和成本优势:
-
阿里云对象存储同城冗余的标准版存储单价为 0.12 元/GiB/月,相较于 ESSD PL1 的单价(1 元/1 GiB/月)便宜 8 倍以上。同时,对象存储天然具备多可用区的可用性和持久性,数据无需额外再做复制,使得相比较传统的基于云盘的 3 副本架构,成本能节省 25 倍。
-
共享存储架构相比较 Shared-Nothing 架构,是真正的存算分离,数据跟计算节点无绑定关系。因此,AutoMQ 在进行分区移动时无需复制数据,能够做到真正的秒级无损分区迁移。这也是支撑 AutoMQ 流量实时重平衡和秒级节点水平扩缩容的原子能力。
S3 存储架构
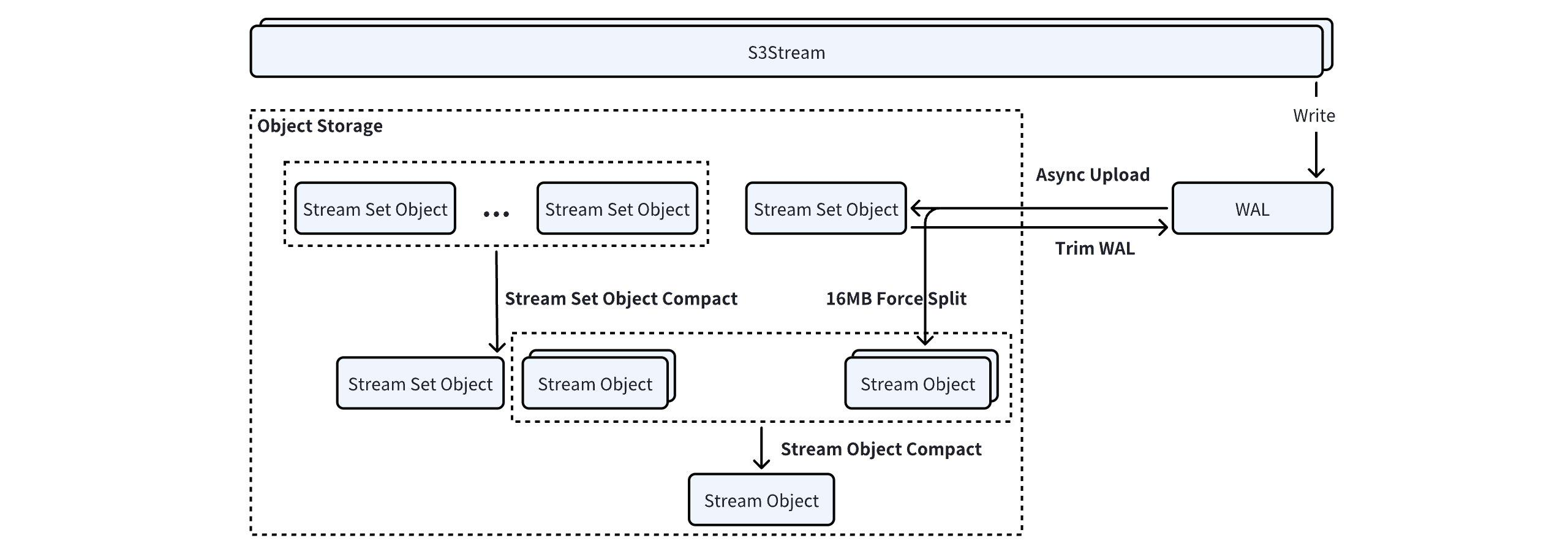 AutoMQ 所有的数据都通过 S3Stream 存储至对象存储,在对象存储中定义了两个 Object 类型:
AutoMQ 所有的数据都通过 S3Stream 存储至对象存储,在对象存储中定义了两个 Object 类型:
-
Stream Set Object: WAL 数据上传的时候,大部分数据量较小的 Stream 会合并作为一个 Stream Set Object 上传。
-
Stream Object: Stream Object 里面只有单个 Stream 的数据,方便对不同生命周期的 Stream 做精细化的数据删除。
Kafka 一个分区的数据会映射到多个 Stream 之上,核心为两个:
-
Metadata Stream: 元数据流保存数据索引、Kafka LeaderEpoch 快照、Producer 快照等信息。
-
Data Stream: 数据流保存分区中完整的 Kafka 数据。
S3 上对象的元数据信息是保存在 KRaft 当中的,为了降低海量分区场景下元数据的规模,S3Stream 内部提供了两种 Compaction 机制,用于合并小对象,从而降低元数据的规模。
StreamSet Object Compact
StreamSet Object Compact 会在 Broker 后台以 20min 的间隔定期执行。类似 RocksDB SST, StreamSet Object Compact 根据策略选取当前 Broker 合适的 StreamSet Object 列表,采用归并排序合并的方式进行合并:
-
对于合并后会超过 16MiB 的 Stream,会分裂出一个单独的 Stream Object 上传;
-
剩余的 Stream 归并排序写入到一个新的 StreamSet Object 中。
归并排序进行 StreamSet Object 的合并,在 500MiB 的内存占用、读写 Range 16MiB 大小下,可以完成至多 15TiB 的 StreamSet Object 的合并。
通过 StreamSet Object Compact,零散的小流量 Stream 数据段,被合并成更大的数据段,对于冷数据 Catch-up Read 的场景,极大的降低读取 API 调用和提升读取效率。
Stream Object Compact
Stream Object Compact 的核心目的是节省集群维护 Object 映射的元数据总量,并且提高 Stream Object 数据的聚合度以减少冷数据 Catch-up Read 的 API 调用费用。
参与到 Compact 的 Stream Object 通常已经是 16MB,满足对象存储的最小 Part 限制。Stream Object Compact 会使用对象存储的 MultiPartCopy API 来直接进行 Range Copy 上传,避免从对象存储读取再写入浪费网络带宽。
多 Bucket 架构
对象存储作为各个云厂商最重要的存储服务,提供了 12 个 9 的数据持久性和高达 4 个 9 的可用性。但软件的故障永远都无法被消除,对象存储依然可能出现重大的软件故障,从而导致 AutoMQ 服务不可用。
另一方面,在云端,多云、多地域、甚至混合云的架构形态逐渐萌芽,以满足企业更灵活的 IT 治理诉求。
鉴于此,AutoMQ 企业版创新性地通过多 Bucket 架构来进一步提高系统的可用性,以及满足企业更灵活的 IT 治理诉求。
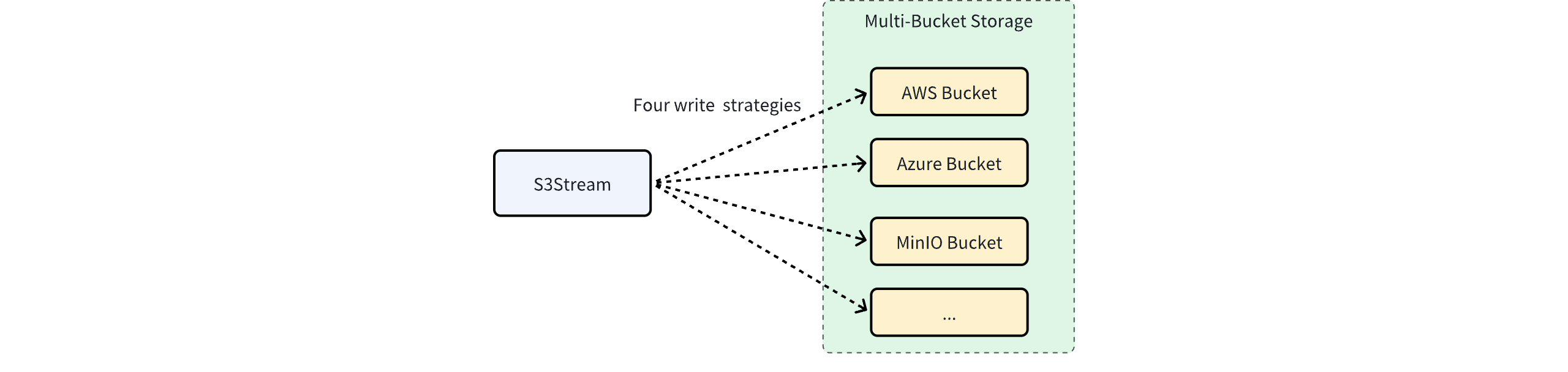 AutoMQ 企业版支持配置 1 个或者多个 Bucket 用于数据存储,同时 S3Stream 支持 4 种写入策略以满足不同的业务场景。
AutoMQ 企业版支持配置 1 个或者多个 Bucket 用于数据存储,同时 S3Stream 支持 4 种写入策略以满足不同的业务场景。
轮询法(Round Robin)
多个 Bucket 被同等对待,以轮询地方式写入。一般用于突破云厂商对单个 Bucket 或者单个账户的带宽限制。比如一个 Bucket 如果仅支持 5GiB/s 的带宽,可以通过组合两个 Bucket 来达到 10GiB/s 的带宽,以支持超大流量规模的业务场景。
故障转移(Failover)
对象存储依然可能出现故障,甚至软件级故障可能比可用区级的故障更严重。对于那些对可用性要求极高的业务场景,可以通过故障转移地方式写入两个 Bucket。故障转移场景下的 Bucket 配置可能为:
-
其中一个作为主 Bucket,跟业务在同地域,数据尽可能写入主 Bucket。
-
在另外一个地域,甚至另外一朵云创建一个备用 Bucket。跟主地域通过专线或者公网的形式打通网络,当主地域的对象存储不可用时,新的数据提交到备用 Bucket。备用链路会付出较高的网络成本,但因为仅发生在主 Bucket 不可用期间,成本相对可控。
该写入策略能极大地丰富 AutoMQ 的容灾场景,可以让 AutoMQ 以低成本的形式构建多地域容灾、多云容灾甚至混合云容灾的架构。
复制(Replication)
故障转移形式的多 Bucket 架构,只能在故障期间对写流量进行转移,读需要延迟读取。如果业务不能容忍故障期间的读延迟,希望是一个读写多活的架构,那么可以将写入策略配置为复制形式,此时数据会同步写入多个 Bucket。
该方式成本非常高,仅适合非常关键的业务。
动态分流(Dynamic Sharding)
数据以一种动态的,可随时调节的比例写入多 Bucket,轮询是该策略的一种特殊场景。动态分流的写入方式往往适用于多云和混合云架构。在该架构中,配置不同云服务的 Bucket,或者组合公共云和私有云的对象存储,同时动态调节流量比例,可以让架构时刻具备多云迁移,甚至下云的灵活能力。