Current State of the Apache Kafka® Protocol
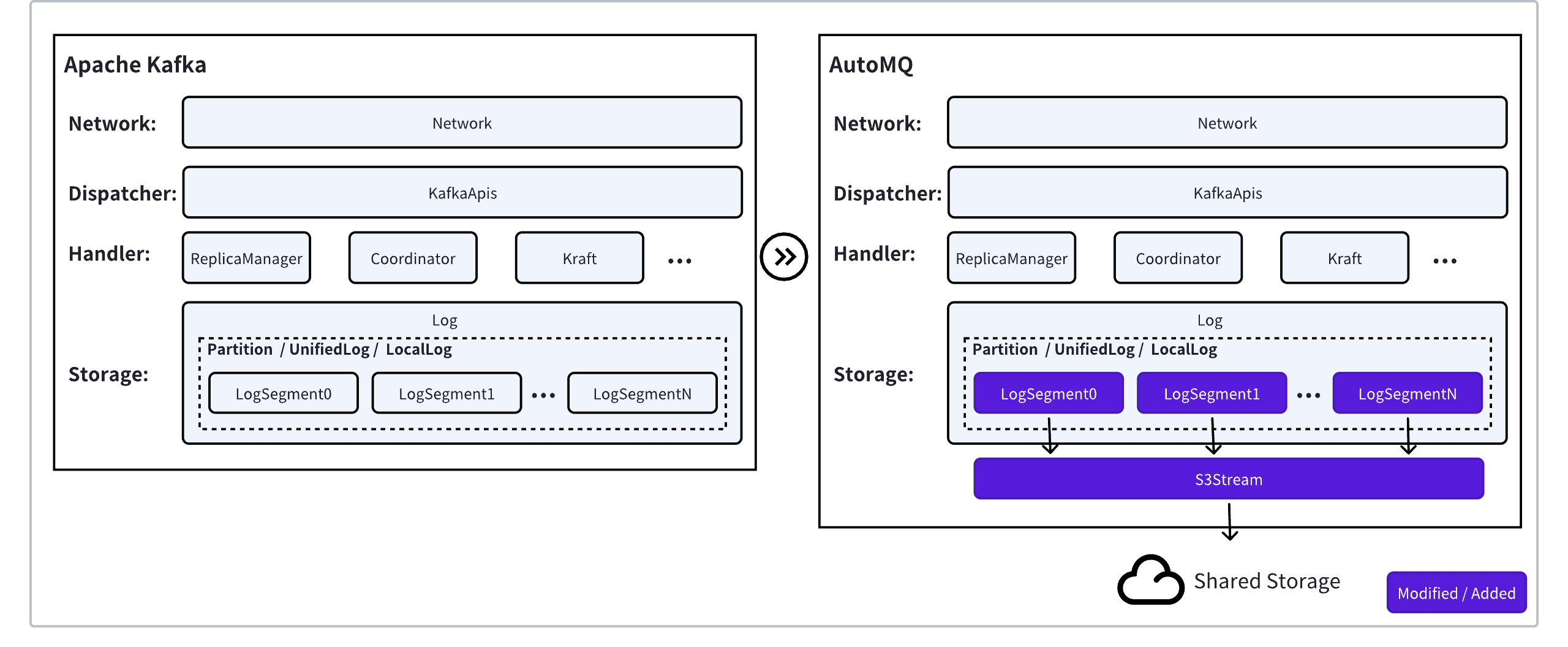
Apache Kafka® has been developed for over 10 years, with contributions from over 1000+ contributors, leading to 1059 KIPs [1]. The entire codebase contains hundreds of thousands of lines of code, incorporating numerous features, optimizations, and fixes. Building a Kafka-compatible API protocol and semantics from scratch would not only require extensive development effort but is also prone to errors. The Apache Kafka® architecture is composed of a compute layer and a storage layer:- Compute Layer: Constitutes 98% of the total codebase, carrying Kafka’s API protocol and features. Additionally, the compute layer has numerous system optimizations tailored for stream storage, such as end-to-end batch design and zero-copy mechanisms, enabling 1GiB/s throughput with just 2 CPU cores.
- Storage Layer: Makes up 2% of the total codebase and is responsible for the high-durability storage of messages. As a stream processing pipeline, Apache Kafka® stores vast amounts of data over time. The majority of the cost for an Apache Kafka® cluster stems from data storage expenses and the costs associated with machines deployed for compute-storage integration.
AutoMQ Natively Supports the Kafka Protocol
AutoMQ aims to upgrade Apache Kafka® to a shared storage architecture by adopting a compute-storage separation architecture. The optimal solution is to replace Kafka’s storage layer while retaining its native compute layer. The advantages of this approach include:- It allows for the reuse of 98% of Apache Kafka’s compute layer code, ensuring API protocol & semantic compatibility and feature alignment.
- It enables the replacement of the storage layer with cloud-native storage services, leveraging the technical and cost benefits of shared storage and cloud-native technologies.